AI 산업이 빠르게 확장되면서 AI 연산을 담당하는 반도체 아키텍처도 세분화되고 있습니다. 초기에는 GPU가 대부분의 AI 워크로드를 처리했지만, AI 모델의 활용 범위가 확대되면서 연산 환경, 전력 제약, 메모리 구조에 따라 다양한 형태의 AI 가속기가 등장하고 있습니다.
특히 최근에는 추론(Inference) 워크로드의 비중이 빠르게 증가하며, 클라우드 서비스뿐 아니라 스마트폰, PC, 로봇, 산업 장비 등 다양한 디바이스에서 온디바이스 AI(On-Device AI) 기능이 구동되는 흐름이 뚜렷합니다. 현재 AI 추론 하드웨어는 아키텍처 설계 목표와 메모리 구조, 전력 효율에 따라 크게 네 가지 영역으로 구분할 수 있습니다.
최근 업무상 On Device AI 관련 내용을 접할 일이 많아서 이 과정에서 NPU 회사들을 센싱해봤는데요, 업무상 이 내용들을 정리한 김에 블로그에 다시 모바일부터 데이터센터까지 Eco를 정리해보려고 합니다.
우선 현재 AI 추론 하드웨어는 크게 다음 네 가지 영역으로 구분할 수 있습니다.
- Mobile / PC SoC NPU
- Edge AI NPU
- Data Center AI Accelerator
- China AI Accelerator Ecosystem
각 영역은 단순히 성능 차이만 있는 것이 아니라 아키텍처 설계 목표와 메모리 구조, 전력 효율, 시장 구조까지 모두 다릅니다.
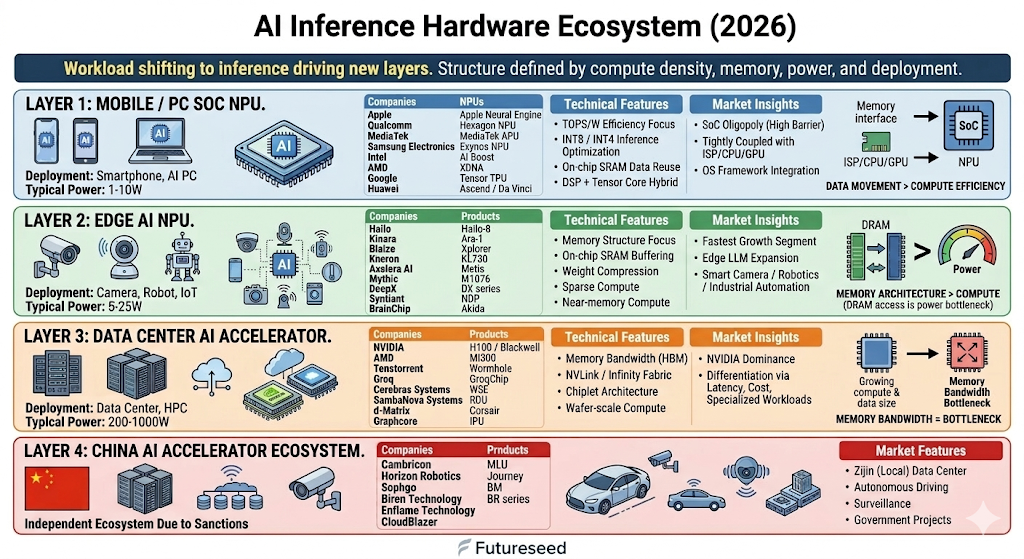
1. Mobile / PC SoC NPU
스마트폰이나 AI PC에서 CPU, GPU와 함께 하나의 SoC에 통합된 AI 연산 유닛입니다. 최근 마이크로소프트의 Copilot+ PC 규격(NPU 40 TOPS 이상)이 등장하면서 연산 성능이 상승하고 있습니다.
| Company | Chip | AI Performance | 특징 |
| Apple | Apple Neural Engine | 38 TOPS (M4) / 18 TOPS (M3) |
Apple Silicon SoC 통합, UMA 구조
|
| Qualcomm | Hexagon NPU | 45 TOPS (X Elite) |
Snapdragon AI Engine, DSP 기반
|
| MediaTek | MediaTek APU | ~48 TOPS (Dimensity 9300) |
Dimensity SoC 통합
|
| Intel | AI Boost | 48 TOPS (Lunar Lake) |
Core Ultra NPU, 타일(Tile) 아키텍처
|
| AMD | XDNA / XDNA2 | 16~50 TOPS |
Ryzen AI, AI 엔진 통합
|
- Apple: A11 칩에서 Neural Engine을 도입한 이후, Apple Silicon으로 확장하며 CPU, GPU, NPU가 메모리를 공유하는 UMA(Unified Memory Architecture) 구조를 확립했습니다. 이 구조는 메모리 복사 병목을 줄여 성능을 극대화합니다.
- Qualcomm: Snapdragon SoC 내부에 Hexagon DSP 기반 AI 가속기를 탑재합니다. Android AI SDK 및 생태계와의 통합 시너지가 강점입니다.
- Intel / AMD: AI PC 시장을 겨냥해 NPU 성능을 크게 끌어올리고 있습니다. Copilot+ PC 전략에 맞춰 40 TOPS 이상의 성능을 달성하며 온디바이스 AI 추론 플랫폼 주도권을 경쟁 중입니다.
- 기술 인사이트: Mobile NPU의 핵심 지표는 전력 효율(TOPS/W)입니다. 모바일 환경은 대역폭 한계로 연산보다 메모리 접근 비용이 크기 때문에, 온칩 SRAM 활용, 데이터플로우 아키텍처, 양자화(INT4/INT8) 기술이 필수적입니다.
2. Edge AI NPU
카메라, 로봇, 드론, 산업 장비 등에 탑재되는 독립형 AI 칩이 주류를 이룹니다. 특정 도메인에 특화되어 범용성보다는 목적에 맞는 전력 효율과 폼팩터 최적화에 집중합니다.
| Company | Chip | AI Performance | Power |
| Hailo | Hailo-8 / 10 | 26 / 40 TOPS | ~2.5W |
| Kinara | Ara-1 | ~20 TOPS | ~3W |
| DeepX | DX-M1 | 25 TOPS | ~5W |
| Axelera AI | Metis | 214 TOPS | ~15W |
| Syntiant | NDP series | >1 TOPS |
~1mW 수준 (초저전력)
|
| Kneron | KL730 | 3~4 TOPS | ~1.5W |
| BrainChip | Akida | Neuromorphic | Ultra-low power |
- Hailo: 이스라엘 기반 기업으로 Edge AI 시장에서 점유율을 넓히고 있습니다. 외부 DRAM 의존도를 낮추고 온칩 메모리와 분산형 아키텍처를 결합하여 전력 효율을 높였습니다.
- DeepX: 한국의 대표적인 AI 반도체 설계 기업으로, 전성비(TOPS/W)에 집중한 아키텍처를 바탕으로 로보틱스, 스마트 카메라, 산업 장비 시장을 공략합니다.
- Axelera AI: SRAM 기반의 디지털 인메모리 컴퓨팅(D-IMC, Digital In-Memory Computing) 아키텍처를 적용하여 데이터 이동 병목을 해결하고 연산 성능을 높였습니다.
- 기술 인사이트: Edge 환경에서는 DRAM 접근 시 발생하는 전력 소모가 치명적입니다. 따라서 가중치 압축(Weight Compression), 희소성(Sparsity) 지원, 인메모리 컴퓨팅 등 메모리 아키텍처 최적화가 칩 설계의 핵심입니다. 최근에는 sLLM을 엣지단에서 추론하는 Edge LLM 시장이 새로운 동력으로 떠오르고 있습니다.
3. Data Center AI Accelerator
초거대 언어 모델(LLM)의 학습 및 클라우드 환경의 대규모 추론을 담당하는 고성능 하드웨어입니다.
| Company | Chip | AI Performance | 특징 |
| NVIDIA | H100 / B200 | 수십 PFLOPS |
GPU 기반, CUDA 생태계, NVLink
|
| AMD | MI300X | ~1.3 PFLOPS |
CDNA 아키텍처, 192GB HBM3
|
| Tenstorrent | Wormhole | 262 TFLOPS (FP8) |
RISC-V 기반 텐서 연산 구조
|
| Groq | GroqChip | Deterministic |
LPU 아키텍처, SRAM 기반 초저지연
|
| Cerebras | WSE-3 | 4,000,000 cores |
Wafer-Scale Engine (웨이퍼 단위 칩)
|
| SambaNova | RDU | Dataflow |
재구성 가능한 데이터플로우 아키텍처
|
- NVIDIA: 데이터센터 시장의 압도적 리더입니다. 하드웨어 성능뿐 아니라 CUDA 기반의 견고한 소프트웨어 생태계가 진입 장벽으로 작용합니다.
- Tenstorrent: CPU 아키텍처의 거장 짐 켈러가 이끄는 기업으로, RISC-V 기반 구조와 자체 네트워크 패브릭을 통해 확장에 용이한 구조를 취하고 있습니다.
- Groq: 외부 HBM을 배제하고 대용량 SRAM을 칩에 내장하여, 모델을 분산 배치하는 LPU(Language Processing Unit) 아키텍처로 초저지연(Ultra-low latency) 추론 타겟팅을 하고 있습니다.
- 기술 인사이트: Data Center 가속기의 가장 큰 병목은 메모리 대역폭(Memory Bandwidth)입니다. 연산 장치 성능을 메모리가 따라가지 못하는 현상을 극복하기 위해 HBM3e/HBM4의 도입, 칩렛(Chiplet) 패키징, 초고속 인터커넥트(NVLink, PCIe Gen5/6, CXL) 기술 발전이 동반되고 있습니다.
4. China AI Accelerator Ecosystem
미국의 고성능 AI 반도체 수출 규제 이후, 중국은 내수 시장(클라우드, 관공서, 자율주행)을 기반으로 독자적인 AI 생태계를 강제 구축하고 있습니다.
| Company | Chip | 특징 |
| Huawei | Ascend 910B / 910C |
중국 내 NVIDIA 대체제로 가장 널리 쓰이는 자체 NPU
|
| Cambricon | MLU series |
클라우드 및 엣지 범용 AI 가속기
|
| Horizon Robotics | Journey series |
ADAS 및 자율주행 특화 프로세서
|
| Sophgo | BM series |
텐서 프로세싱 특화 하드웨어
|
| Biren Technology | BR series |
범용 GPGPU 아키텍처 기반
|
- Huawei: 미국의 제재 속에서도 Ascend 910 시리즈와 자체 프레임워크인 CANN을 통해 중국 데이터센터 시장에서 사실상의 NVIDIA 대체재 역할을 수행하고 있습니다.
- 시장 인사이트: 선단 파운드리 공정 활용에 제약이 있어, 물리적인 칩 크기를 키우거나 구형 칩렛 패키징 방식을 통해 성능을 보완하려는 움직임이 뚜렷합니다.
참고: 이 글의 일부 내용은 AI를 활용하여 데이터를 센싱 및 정리한 것으로, 기업별 세부 스펙이나 급변하는 칩셋 시장 상황에 오류가 포함되어 있을 수 있으니 인사이트 참고용으로만 활용하시기 바랍니다.
'Investment & Economy' 카테고리의 다른 글
| 브로드컴 분석 Google TPU 인프라 공급 및 VMware 기반 수익 구조 (0) | 2026.03.29 |
|---|---|
| Ondo Finance 분석 RWA 관련주, 하락장의 고통에서 분석 (0) | 2026.03.24 |
| 아이엘사이언스(307180) 상승이유는? 분석 및 리스크 점검 (0) | 2026.03.12 |
| Gemini 와 함께 미국 기업 분석: 오스카 헬스(OSCR) — 사업 내용 및 유망할 수 있는 이유와 리스크 분석 (0) | 2026.02.24 |
| 리커젼 파마슈티컬스(RXRX) 임상 발표 결과 분, REC-4881 TUPELO 임상 1b/2상 중간 결과 정리 (0) | 2025.12.23 |